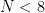Matrix4fはMatrix4dより速い?
Eigenを使う理由の一つに自動ベクトル化がある.例えば,ベクトルの大きさがSSEであれば128bit (float x 4),AVXであれば256bit (float x 8)以上であれば自動的にSIMD演算を使って処理を高速化してくれる.このときにスカラ型をdoubleでなくfloatにしておけば同時にたくさんのデータを処理できるのでより速くなる...と昔ベンチマークをして思っていたのだが,必ずしもそうでもないことに最近気がついた.せっかくなので最近取り直したベンチマークの記録を残しておく.
ベンチマークに使う式はなるべく実際の用途に近いものが良かったのでGICPコスト風の以下の式を使った(比較を簡単にするため逆行列は外した).
この式の次元数 

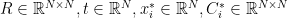

上図のAVXの結果を見てみると,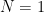
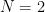



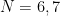
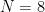
下図のAVX無効でSSEのみ有効のときも基本的には似たような傾向であるが,
まとめ
処理に使う数式やプログラム構造にもよるが,AVXを使える場合には基本的にdoubleを使っておくのがいいように思う.特に