FP16(半精度浮動小数点)を省メモリ・高速化用に使ってみたいと思い,どの程度の精度があるのか気になった.FP16は仮数部は11bitなので2048段階=10進数3桁ちょっとの精度があるが,それに指数部がかかってきたときの実際の精度を調べてみた.簡単に精度を測るために,細かいステップ(e.g., 1e-4)で変化するFP32を一度FP16に落として,再びFP32に戻したときの一定区間における前後数値差の最大値をFP16の解像度として調べた.今回は点群処理への利用を考えているので,x < 1000 の範囲を使った.
Range : Max delta error (Resolution)
< 0.01 : 0.000100
< 0.1 : 0.000130
< 1.0 : 0.000490
< 10.0 : 0.007820
< 100.0 : 0.06250
< 1000.0: 0.5

結果としては,だいたい距離で考えると10m程度までなら8mm,100mまでなら6cm,1000mまでなら50cmくらいの解像度がありそうという感じだった.いろいろ演算することを考えると点群処理には結構ギリギリな感じだろうか.メモリ節約用に部分的に使うことはできそうかも.

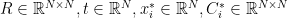
 を変えたときに秒数あたりに処理できる点数を計測した結果が以下である.縦軸(対数表示)が大きいほどたくさんのデータを処理できる=処理速度が速いということになる.上図はAVXを有効にしてビルドした結果,下図はSSEのみ有効でビルドした結果となっている.
を変えたときに秒数あたりに処理できる点数を計測した結果が以下である.縦軸(対数表示)が大きいほどたくさんのデータを処理できる=処理速度が速いということになる.上図はAVXを有効にしてビルドした結果,下図はSSEのみ有効でビルドした結果となっている.
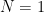 のときはfloatもdoubleもSIMDが使えないので全く同じ処理速度になっている.
のときはfloatもdoubleもSIMDが使えないので全く同じ処理速度になっている.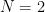 および
および のときはdoubleのほうが大幅に速い.これはfloat x 3 = 96bitだと小さすぎてSSE演算すら使えないのに対して,double x 3 = 192bitなら128bitよりは大きいため一部の計算にはSSEが使えるからである.floatは
のときはdoubleのほうが大幅に速い.これはfloat x 3 = 96bitだと小さすぎてSSE演算すら使えないのに対して,double x 3 = 192bitなら128bitよりは大きいため一部の計算にはSSEが使えるからである.floatは のときにようやくSSEが使えるようになるので大幅に高速になるが,doubleもAVXで4データ同時処理できるためほぼ同速度になっている.その後も
のときにようやくSSEが使えるようになるので大幅に高速になるが,doubleもAVXで4データ同時処理できるためほぼ同速度になっている.その後も のときはわずかにfloatが速いが,
のときはわずかにfloatが速いが,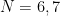 のときは細かい粒度でSSEを使えるdoubleのほうが速い.安定してfloatのほうが速くなるのはAVXの256bit幅を超える
のときは細かい粒度でSSEを使えるdoubleのほうが速い.安定してfloatのほうが速くなるのはAVXの256bit幅を超える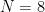 以上になってからのようだ.
以上になってからのようだ.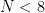 の低次元においてはfloatはAVXを活用できないため速度的なアドバンテージはほとんど期待できない(むしろキャストなどで遅くなることもままある).今回は固定サイズ行列でテストしたが動的サイズでも似たような傾向になるのかなと思う.AVXが使えないようなCPU(ARM除く)を使っている場合には早急に買い替えたほうがいいと思う.
の低次元においてはfloatはAVXを活用できないため速度的なアドバンテージはほとんど期待できない(むしろキャストなどで遅くなることもままある).今回は固定サイズ行列でテストしたが動的サイズでも似たような傾向になるのかなと思う.AVXが使えないようなCPU(ARM除く)を使っている場合には早急に買い替えたほうがいいと思う.